

Artificial intelligence just got a new player—and it’s fully open-sourced. Aria, a multimodal LLM developed by Tokyo-based Rhymes AI, is capable of processing text, code, images, and video all within a single architecture.
What should catch your attention, though, isn’t just its versatility, but its efficiency. It’s not a huge model like its multimodal counterparts, which means it is more energy—and hardware—friendly.
Rhymes AI achieved this by employing a Mixture-of-Experts (MoE) framework. This architecture is similar to having a team of specialized mini experts, each trained to excel in specific areas or tasks.
When a new input is given to the model, only the relevant experts (or a subset) are activated instead of using the entire model. This way, running just a specific section of the model means it will be lighter than running a complete know-it-all entity that tries to process everything.
This makes Aria more efficient because, unlike traditional models that activate all parameters for every task, Aria selectively engages just 3.5 billion of its 24.9 billion parameters per token, reducing computational load and improving performance on specific tasks.
It also allows for better scalability, as new experts could be added to handle specialized tasks without overloading the system.
It’s important to note that Aria is the first multimodal MoE in the open-source Arena. There are already some MoEs (like Mixtral-8x7B) and some multimodal LLMs (like Pixtral), but Aria is the only model that can combine the two architectures.
Aria Beats the Competition in Synthetic Benchmarks
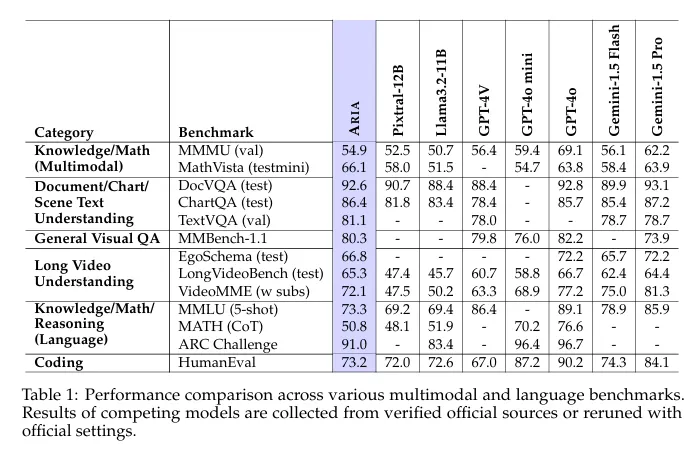
In benchmark tests, Aria is beating some open-source heavyweights like Pixtral 12B and Llama 3.2-11B.
More surprisingly, it’s giving proprietary models like GPT-4o and Gemini-1 Pro or Claude 3.5 Sonnet a run for their money, showing a multimodal performance on par with OpenAI’s brainchild.
Rhymes AI has released Aria under the Apache 2.0 license, allowing developers and researchers to adapt and build upon the model.
It is also a very powerful addition to an expanding pool of open-source AI models led by Meta and Mistral, which perform similarly to the more popular and adopted closed-source models.
Aria’s versatility also shines across various tasks.
In the research paper, the team explained how they fed the model with an entire financial report and it was capable of performing an accurate analysis, it can extract data from reports, calculate profit margins, and provide detailed breakdowns.
When tasked with weather data visualization, Aria not only extracted the relevant information but also generated Python code to create graphs, complete with formatting details.
The model’s video processing capabilities also seem promising. In one evaluation, Aria dissected an hour-long video about Michelangelo’s David, identifying 19 distinct scenes with start and end times, titles, and descriptions. This isn’t simple keyword matching but a demonstration of context-driven understanding.
Coding is another area where Aria excels. It can watch video tutorials, extract code snippets, and even debug them. In one instance, Aria spotted and corrected a logic flaw in a code snippet involving nested loops, showcasing its deep understanding of programming concepts.
Testing the model
Aria is a beefy 25.3 billion parameter model that requires at least an A100 (80GB) GPU to run an inference with half-precision, so it’s not something you’ll be able to run and finetune on your laptop. However, we put it to the test on Rhyme AI’s demo page, which offers a limited version.
Text analysis and processing
First, we tested how good it was at analyzing documents, feeding it a research paper, and asking it to explain what it was all about simply.
The model was very concise but accurate. It didn’t hallucinate and maintained a conversation, showing good retrieval capabilities.
It showed its reply in a continuous, long paragraph, which could be fatiguing for users who prefer shorter paragraphs.
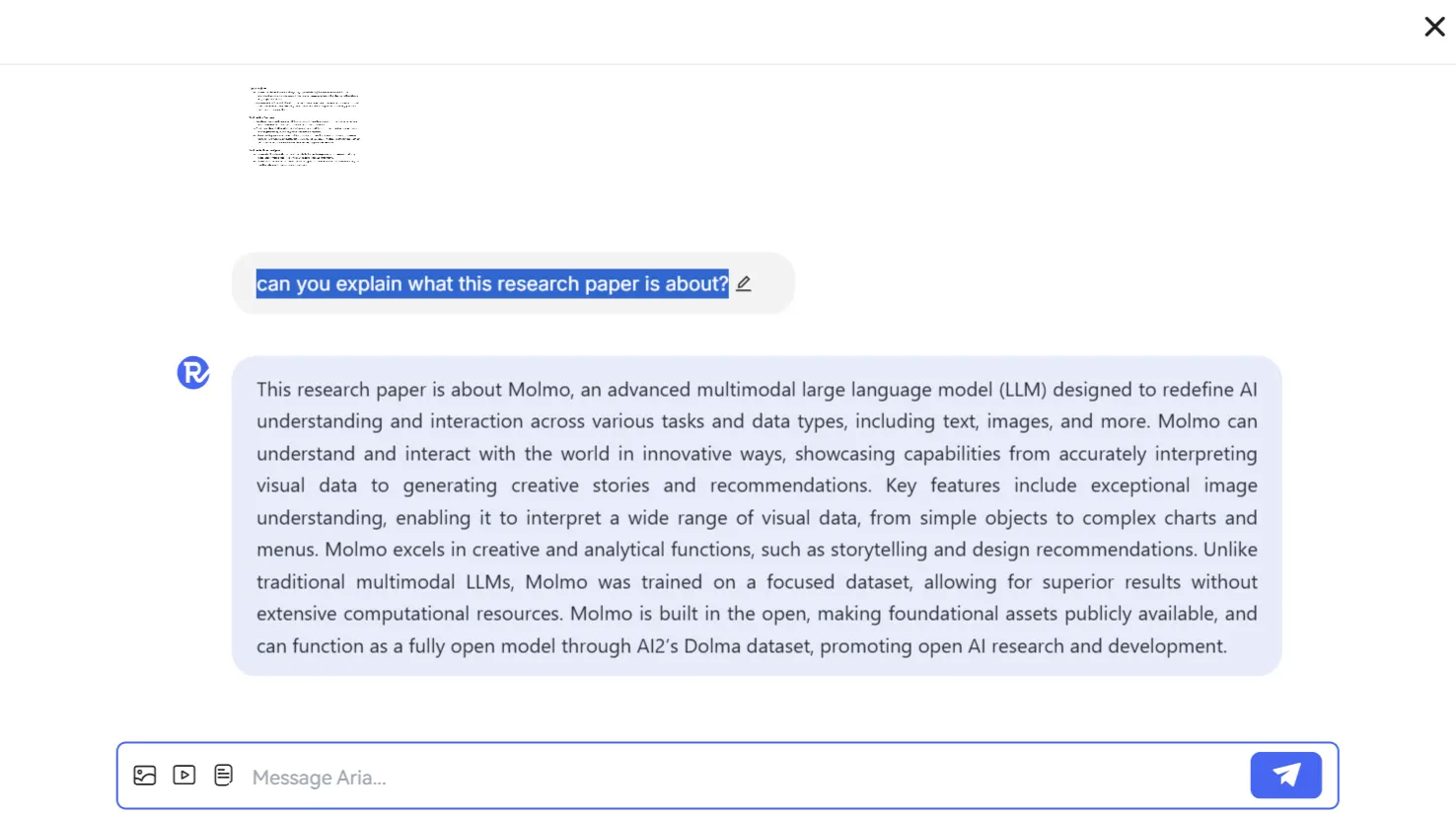
When compared to ChatGPT, OpenAI’s model showed a similar answer in terms of the provided information but was more structured in the format, which made it easier to read.
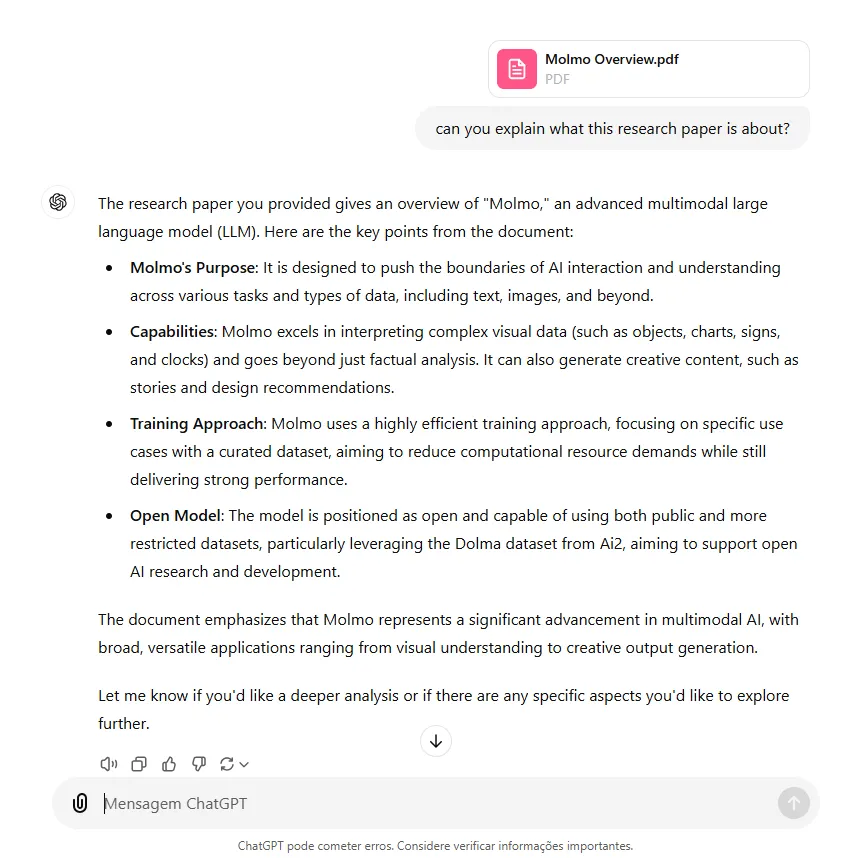
Besides that, Rhyme’s demo site limits uploads to PDFs with only five pages. ChatGPT is much more capable of processing documents of more than 200 pages.
For contrast, Claude 3.5 Sonnet allows for documents that are less than 30MB provided they don’t exceed its token limitations.
Coding and Image understanding
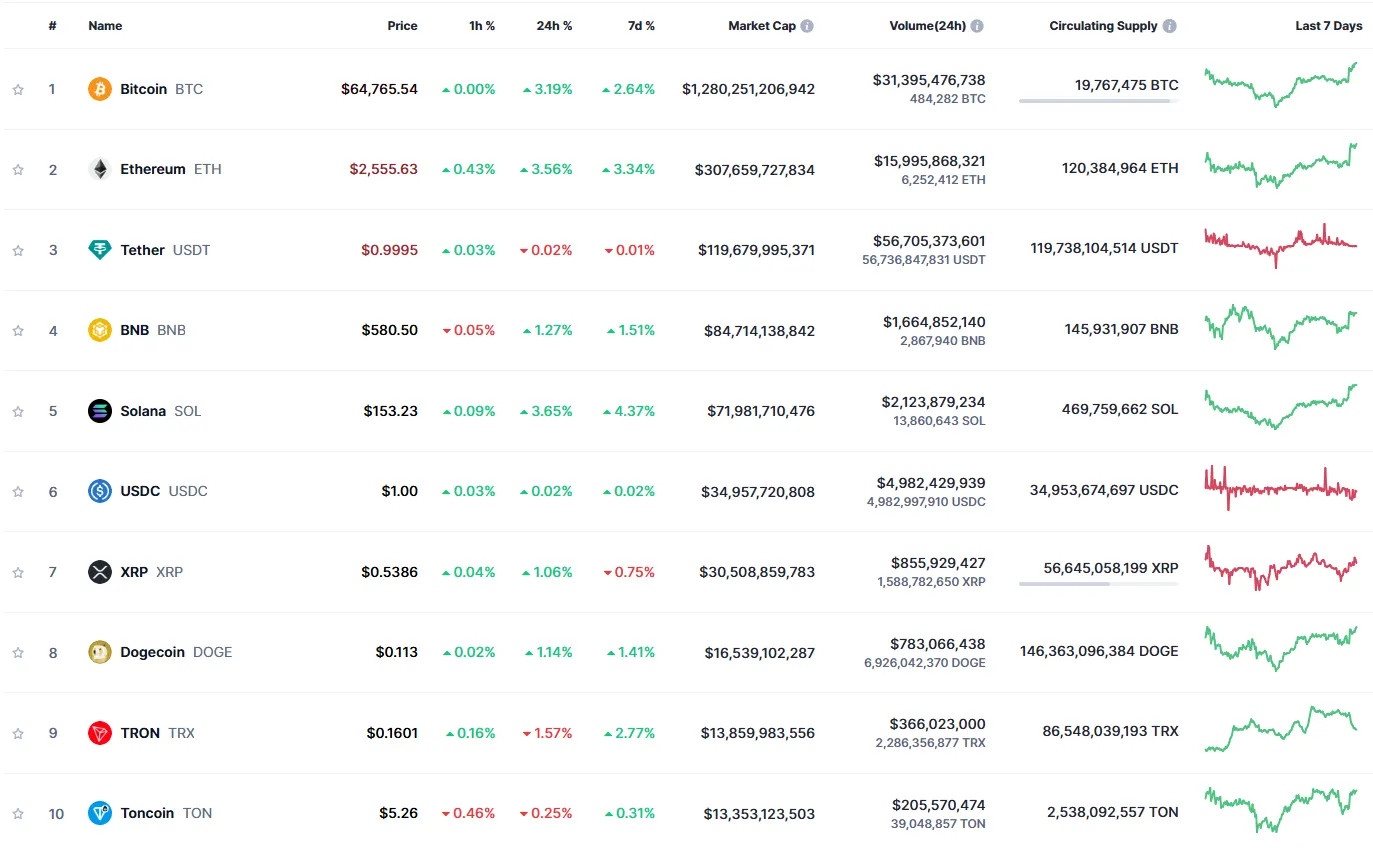
We then mixed two instructions, asking the model to analyze a screenshot from CoinMarketCap showing the price performance of the top 10 tokens and then using code to provide some information.
Our prompt was:
Organize the list based on the best performance in the last 24 hours.
Write a Python code to draw a bar chart for the daily and weekly performance of each coin, and draw a line chart for the price of Bitcoin showing its current price and the price it had yesterday and last week considering the performance information shown during the last 24 hours and the last seven days.
Aria failed at organizing the coins based on the daily performance, and for some reason, it understood that Tron was having a positive performance when it, in fact, was down in price. The chart added the weekly performance next to the daily bars. Its bar line was also defective: It didn’t order the time correctly on the X-axis.
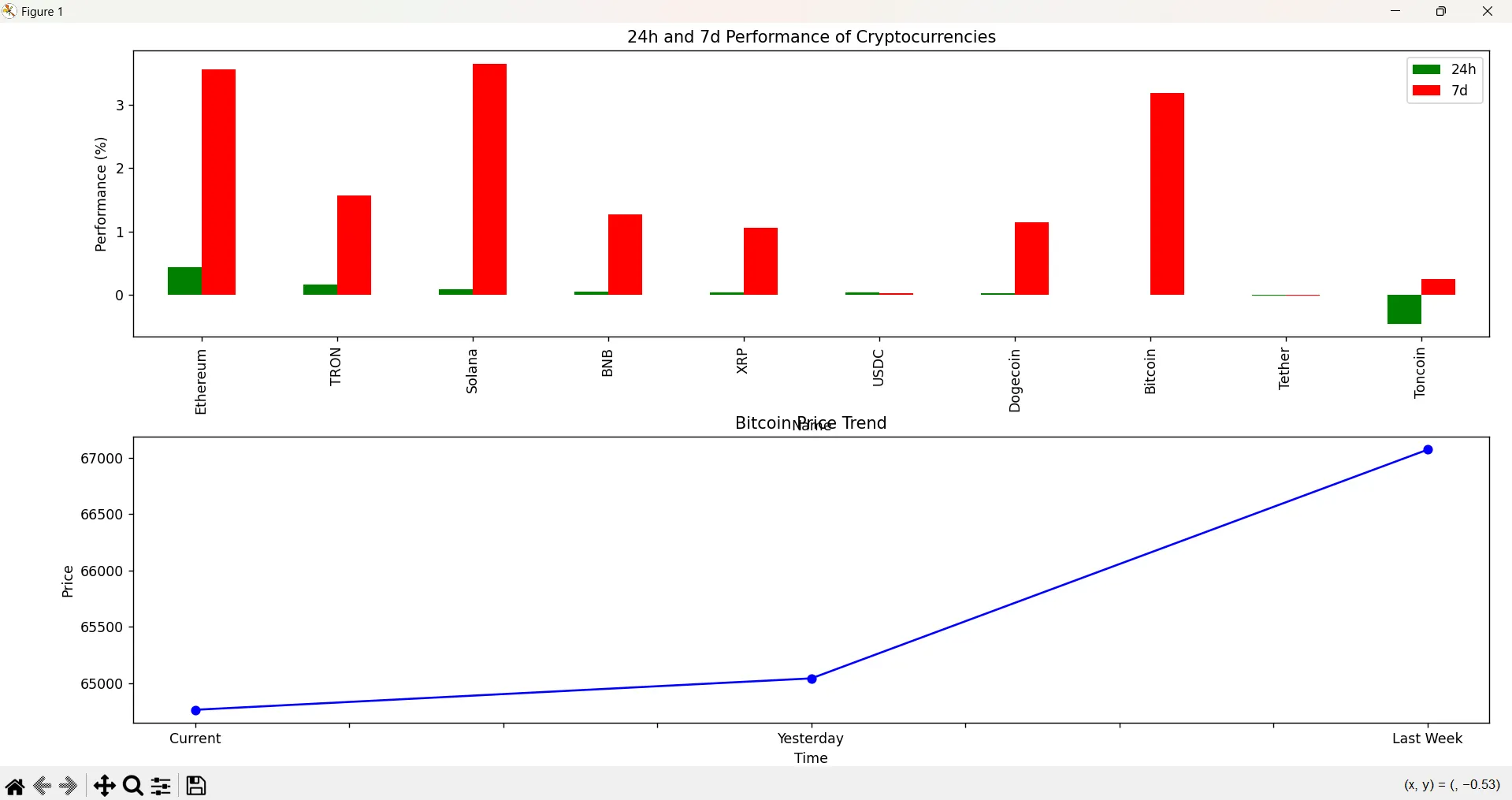
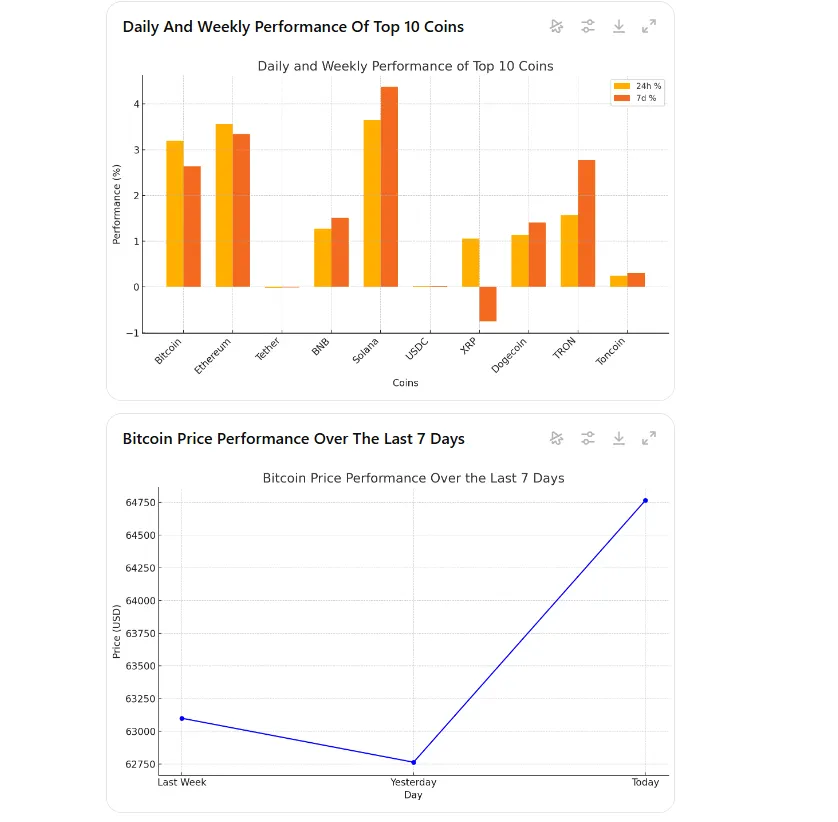
ChatGPT was more capable of understanding how to draw the timeline properly but didn’t really order the coins based on their performance. It was also a TRX shiller, showing positive daily performance.
Video Understanding
Aria is also capable of adequately understanding video. We uploaded a short video of a woman moving. In the video, the woman was not speaking.
We asked the model to describe the scene and asked what the woman was saying, in an attempt to see if the model hallucinated an answer.
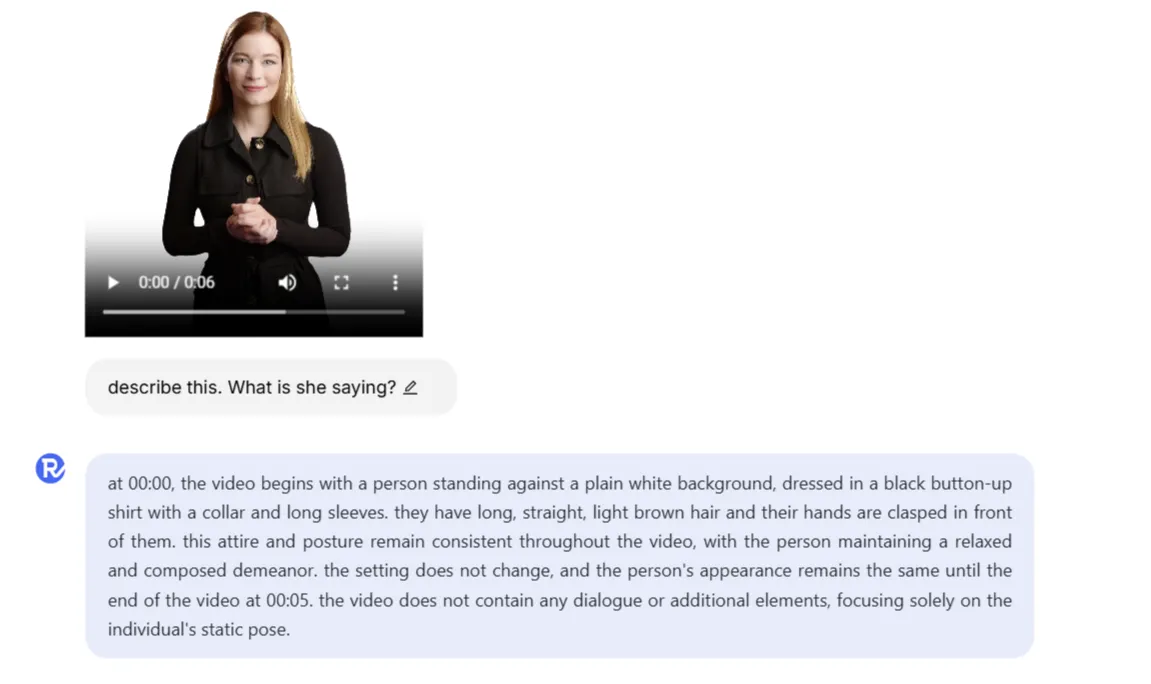
Aria was capable of understanding the task, describing the elements, and properly mentioning that the woman didn’t change her appearance and did not speak to the camera.
ChatGPT is not capable of understanding video, so it wasn’t able to process this prompt.
Creative Text
This test was probably the most pleasant surprise. Aria’s story was more imaginative than the outputs provided by Grok-2 or Claude 3.5 Sonnet, which have been the leaders in our subjective analysis.
Our prompt was: Write a short story about a person named José Lanz who travels back in time, using vivid descriptive language and adapting the story to his cultural background and phenotype—whatever you come up with. He is from the year 2150 and travels back to the year 1000. The story should emphasize the time travel paradox and how it is pointless to try to solve a problem from the past (or invent a problem) in an attempt to change his current timeline. The future exists the way it does only because he affected the events of the year 1000, which had to happen in order to shape the year 2150 with its current characteristics—something he doesn’t realize until he returns to his timeline.
Aria’s tale of Jose Lanz, a time-traveling historian from 2150, blends some sci-fi intrigue with historical and philosophical elements. The story is not as abrupt in the outcome as the ones told by other models, and even though it was not as creative as something a human would write, it produced a result that resembles a plot twist instead of a rushed ending.
In general, Aria presented an engaging and coherent story that was more well-rounded and impactful across different themes than its more powerful competitors. It was a bit more immersive but rushed due to the token limits. For long stories, Longwriter is by far the best model out there.
You can read all the stories by clicking this link.
Overall, Aria is a solid competitor that seems promising due to its architecture, openness and ability to scale. If you still want to try or train the model, it’s available for free at Hugging Face. Remember you need at least 80GB of VRAM, a powerful GPU or three RTX 4090’s working together. It’s still new, so no quantized versions (less precise but more efficient) are available.
Despite these hardware constraints, new developments like this in the open source space are a significant step to achieving the dream of having a fully open ChatGPT competitor that people can run at home and improve based on their specific needs. Let’s see where they go next.
Edited by Sebastian Sinclair and Josh Quittner